TLDR. Eight months ago I wrote a piece called AI Native Development: Thoughts & Questions, honestly labelled as thoughts and questions. I had not built anything substantial yet. Now I have, with Storm2Flow in production and an actual operating system around two adversarial agents. Several of my October assumptions look different. The hard part turned out to be the wrapper, not the agents. The next hard part is what happens when this scales beyond one person.
In October 2025, I wrote down my thoughts and questions about AI-native development. I was honest that they were thoughts and questions. I had not yet built anything substantial in this setup. Adrian Cockcroft had, and his piece inspired mine. Matthias Patzak asked good questions. I joined the conversation as a thoughtful observer.
Eight months later, I have built something. Storm2Flow, in beta, DSGVO-compliant, multi-tenant, EU-hosted. Not a toy. And several of the assumptions I made in October look different from where I sit now.
A note on how I learned what follows. I respect theory and I usually combine it with practice. In this field I deliberately weighted empirical learning higher than I normally do. The writing on agentic development is still thin, the loudest voices are often the least tested, and most of the popular advice in 2026 is restatement of the same handful of practices. I wanted to see if I could find my own way before letting other people’s frameworks shape mine. What follows is the result of that choice.
This is the update.
The first thing that broke
I started with just Claude. One agent, full attention, a clear product idea.
It did not work. Not because Claude was bad, it was not. But because Claude has a tendency to find the first fix to the problem in front of it, regardless of whether the path leads somewhere sensible. I called it short blanket syndrome. You pull the blanket over your feet, your head freezes. You fix the head, your feet freeze.
I lost a few weeks to this before I changed the setup.
The change was to bring in a second agent, Codex, not as a backup but as an adversary. Claude proposes, Codex challenges. Or the other way around. They argue until they converge, or until I decide. Then we move.
This is the pattern I now consider non-negotiable for serious AI-native work. Not one agent, two agents in deliberate disagreement, with me as the arbiter. In the original conversation, “a swarm of collaborating agents” was the shared vocabulary (Adrian Cockcroft’s phrase, I picked it up). That framing is too generous. Collaborating agents agree too quickly. You want adversarial agents that force each other to defend their plans.
Real adversarial pairing needs two genuinely different systems, not one system pretending to be several.
Before I went to two different models, I tried the obvious shortcut. I asked Claude to play several roles, senior engineer, architect, UI engineer, reviewer. It improved things a little. But the personas behaved like engineers from the same agency who are about to ride home together. They disagreed politely, then aligned quickly, then moved on. Their blind spots overlapped because their training did.
None of this is new wisdom. I use the same logic in sourcing strategy: never rely on a single nearshore partner, competition keeps both honest. Many of the lessons from leading engineering teams transfer directly to leading agents. I will write about that separately.
The thing I underestimated
In October I focused on speed. Hours instead of sprints. Build-Measure-Learn cycles compressed. The exciting part.
The exciting part turned out to be the small part.
The real work, the work that took weeks to set up and is the actual reason Storm2Flow exists, is the operating system around the agents. Not the agents themselves.
What that operating system looks like, concretely:
- A backlog, with explicit lifecycle states: idea, doing, waiting-acceptance, done. Every item moves through them on purpose.
- A signal protocol so I can interrupt mid-flow without losing context.
- Founder Acceptance as a hard gate. Nothing is done because the agent says it is done. It is done when I have looked at the rendered thing and accepted it.

- Bug IDs, treated as first-class artifacts. So I can reference, defer, prioritize.
- Plain-language direction, not specifications. “The comment window should not be open by default” beats a paragraph of acceptance criteria.
- Mockup-first for anything UI. I look at the rendered thing before I accept anything. Tests can be green and the thing can still be wrong.
- Cost guardrails as a first-class concern. I learned this the expensive way. A perfectly correct bug fix in one of my agents unblocked a backlog of work that should have stayed queued, and the agents happily processed it. Ten dollars in API tokens before I noticed. The system now treats any billable code path the way it treats errors: declared budget cap, structured spend logging, alerts on the rising edge, and explicit opt-in for backlog replay.
- A dismissed-ideas section in release notes. I will come back to this.
None of this is exciting. All of it is the reason the setup works.
The system itself is now open source at github.com/LuizStruct2Flow/blueprint. I will write a dedicated piece on it next, with the rationale behind each capability. For this article it is enough to say: it exists, it is overprovable, and it lives in code, not in slides.
The honest reason I could build this operating system is almost thirty years of engineering and leading engineers. The patterns are not AI patterns, they are quality-is-speed patterns. Lifecycle discipline, acceptance gates, build-test-deploy hygiene, plain-language requirements. AI did not teach me these. It made them more important.
If you try to do AI-native development without that engineering foundation, I think you are doomed. Not because AI is dangerous, but because AI is fast, and speed without discipline accumulates accidental complexity faster than any team can sort out.
What I was right about, with corrections
On Lean Startup on Steroids. I argued that AI-native development reinforces, not replaces, Build-Measure-Learn cycles. Validation has to happen quickly, otherwise we drown in unvalidated code piled on more unvalidated code. I framed Excellence in Production as the goal, not Development Speed. Both of those still hold, and I would say even more strongly now. With the guardrails in place, the cost difference between building an MVP and building it production-grade has collapsed. The question is no longer “shall we cut corners to validate fast”, it is “what is worth keeping after the validation”. Speed without Excellence is still waste. The two are no longer a trade-off, but the discipline of killing cleanly is what makes that possible.
On BDD and tests as documentation. Right. Storm2Flow has full test coverage including E2E and screenshot tests. The tests are documentation. They are also how I judge quality on parts of the code I cannot read closely. Bugs do appear, but they are typically fixed in minutes, which is itself a quality metric.
On killing quickly. I warned that without disciplined killing and cleanup, we would end up with a complexity avalanche, code piled on code with low business value. That was right. What I had not anticipated is how much killing actually happens in this setup, and how it requires its own discipline to be visible. I now keep a permanent section in my release notes for dismissed ideas. It is one of the most useful parts of the document, because it captures why paths were not taken. In the old world this knowledge would be lost. In the AI-native world it is the difference between a clean codebase and an avalanche I cannot defend against.
On “You Build It, You Run It” under pressure. I argued that AI-acceleration puts the YBIYRI principle under stress, because the code-to-responsible-people ratio explodes, MTTR matters more not less, and we need agents to do SRE work too. I framed it as “Excellence in Production over Development Speed”. Eight months later I would say I had the right diagnosis but the wrong solution path. The fix is not to ask the agents to do SRE work alongside development. The fix is to bake observability, alerting, and run-time discipline into the operating system around them, so that “you run it” becomes structurally easier even as the code volume grows. This is also where the agents themselves benefit: when a problem hits production, the same observability layer that protects MTTR makes root-cause analysis dramatically faster for the agents to perform. The two-commit pattern (reproducer test first, then fix) lives in the same logic: it forces the cause to be made explicit before the cure, which is exactly what an agent needs to operate efficiently.
Excellence in Production stays the goal. The mechanism is the wrapper, not more agent responsibility.
On the Mastery question. I asked whether becoming faster and more autonomous would erode our mastery, and whether we would become increasingly dependent on AI and less capable of working independently. Eight months later, my answer is a partial yes. The mastery that lived in writing code is genuinely getting weaker for me. I do not exercise it daily anymore. I read less code than I used to. What replaces it is a different mastery: setting the conditions in which the code gets written well, direction, standards, acceptance, taste. That mastery is harder to teach and harder to hire for. But I want to be honest that the old skill is atrophying. Whether that is a fair trade depends on what kind of engineer you want to be in five years.
What I was wrong about, or partially wrong
On Build vs Buy moving heavily towards open source and building it yourself. This was Adrian’s framing in the original conversation, and I agreed with the direction in my October piece. I would now soften it. Generation cost has collapsed, so building looks cheap. But TCO has three dimensions: development, complexity, and operations. Cheap to build does not mean cheap to own. I have one hard example: I retired ReactFlow as the engine for diagrams in Storm2Flow. I thought it could be made to work. After living with it, I now believe only excellent UI engineers can make complex diagram editing right, and even with two strong agents, I was not going to bridge that gap myself. The buy-side of that decision was real. I underestimated it.
The corrected version of the principle: AI lowers the cost of building, which makes Build-vs-Buy a more interesting question than before, not a settled one. Some commodities are still cheaper to buy. Some specialized depth still demands either deep human expertise or a real team. The default does not become “build everything”. It becomes “decide more carefully, because the option to build is real where it was not before”.
On AI-native not being just about AI. I wrote this in my conclusion, but I framed it as “we still rely on humans to scale, to own, to tell AI what to build”. That framing is right but incomplete. What I missed is that the humans-still-matter point translates into something very concrete and very engineering-specific: the operating system around the agents. Not just product owners and decision-makers staying important, but a tooling, lifecycle, and discipline layer that has to exist for the agents to deliver anything reliable. The wrapper is the hard part, and I underestimated how much engineering it takes to build it.
The thing I did not see coming
When I started, I expected the hard problem to be: how do I get the agents to produce good code?
That is not the hard problem. With the operating system I described, the agents produce good code. They produce a lot of it.
The hard problem, the one I am sitting with right now, is what happens next.
In a solo setup, with two adversarial agents and one human (me), the system holds together because there is exactly one acceptance authority, one editorial spine, one taste. The agents drift, I yank them back. The agents disagree, I decide. The agents finish, I accept. The bottleneck is my acceptance capacity, and I can feel it. Things accumulate in “waiting acceptance” faster than I can sweep them into “done”.
If this is the bottleneck in a one-person system, what happens when it is a team?
What happens when five humans and ten agents need to share an editorial spine, a signal protocol, lifecycle discipline, acceptance gates? When different humans hold different parts of the product line and the agents drift in different directions for each of them? When agentic output is fast and human coordination is slow?
I do not know the answer yet. I have a strong suspicion that the cost will not be in the agents. It will be in the friction between humans coordinating across agentic speed.
Acceptance, alignment, taste, those are human-bandwidth-constrained activities, and agentic systems generate work faster than human bandwidth can absorb it.
That is the next problem worth writing about. But it is also not where most leadership conversations are right now.
The reason is not that CTOs are slow. The reason is that their professional formation gave them no template for this. The journey from Junior to CTO over the last twenty years moved through XP, Agile, Clean Code, Functional Programming, Microservices, Cross-Functional Teams, Domain-Driven Design. Every one of those was disruptive, but each came with books, conferences, coaches, communities, and time to adapt. The rules were written before most teams adopted them.
This shift is different. The rules are still being written, by people like us, in real time. The pull is on both sides at once: the automation potential and the efficiency gains, against the risk of agents doing things that are not secure, not compliant, not what was asked. Hanging between the two poles is the default position, waiting for clarity that has not arrived yet.
My advice: do not wait for clarity. Install VS Code, use Codex, use Claude Code, generate something, anything. Otherwise you will be making decisions about a reality you have only read about.
The gap between people who have built something with these tools and people who have only talked about them is widening every month, and that gap is going to be expensive on the wrong side of it.
I do not have the full answer to where this leads. I have the shape of it.
A longer arc, revisited too
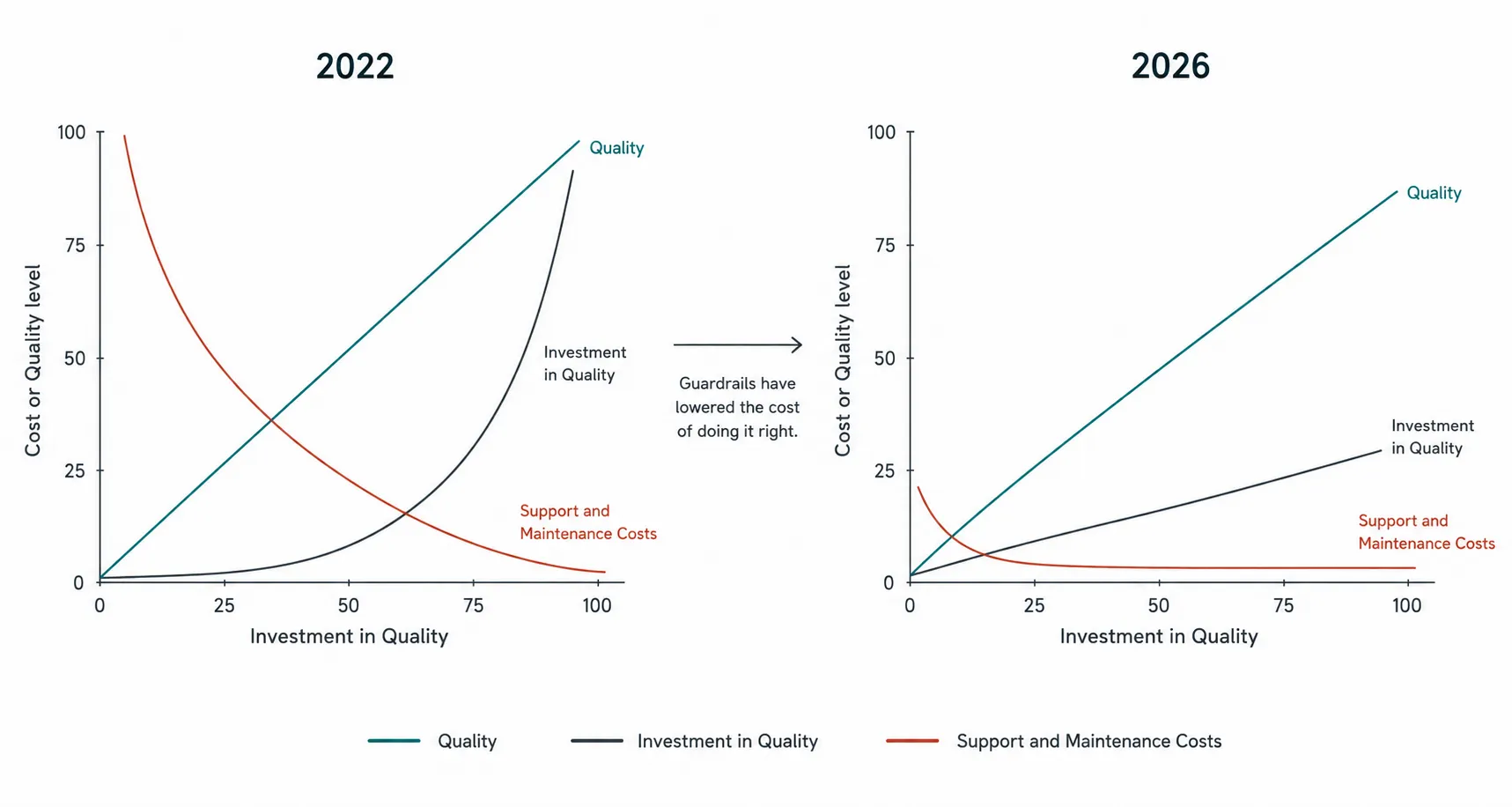
Looking back further than the October piece, in 2022 I wrote about whether to invest in software quality or speed. My answer back then was both, but on different occasions. Two ways of working: one for MVPs in discovery, one for what goes into the platform. Two definitions of done. The reasoning was sound. Engineering resources were expensive, and you could not afford to put full production rigor into every experiment. The core had to be uncompromised, the MVPs had to be killed cleanly. I was explicit about both.
What I underestimated was not the theory. I knew the failure mode: MVPs leaking into the platform, “we will fix it later” promises quietly broken, engineers paying the bill in compounded organisational debt. I had seen it happen many times. The point of the 2022 article was precisely to argue against it. What I underestimated was how hard the discipline of cleanly killing MVPs is in practice, even when the leadership agrees it should happen. The default outcome of a successful MVP is that it becomes a half-supported production system that nobody owns and nobody dares retire.
The setup I have today changes the calculation. With the right guardrails in code, pre-push gates, coverage thresholds, two-commit pattern, cost caps, lifecycle gates, the marginal cost of doing it right is no longer significantly higher than the marginal cost of doing it fast.
You do not need two definitions of done anymore. One disciplined definition, applied through tooling, gets you both.
I will write about that separately too.
Where this leaves me
The original piece ended with a hedge: AI-native is not just about AI, we still need humans, we need to design with them in mind.
Eight months later, I would put it more sharply. The agents are the easy part. The operating system around the agents is the medium part, and it is mostly transferred engineering discipline, not new AI knowledge. The hard part is what happens when this scales beyond one human at the center. That is the actual frontier, and I do not think most organizations are ready for it.
I will write more about that next.
Related
- The original: AI Native Development: Thoughts & Questions. October 2025.
- Should You Invest in Software Quality or Speed?. November 2022. The article I am partly revisiting here.
- Architecture follows Structure. Structure follows Business.. Why most transformations treat the wrong layer.
- Storm2Flow. The product I built while learning all of this. In beta.
- The Blueprint. The operating system itself, open source. Dedicated article coming next.